VGGNet
Legend 13 (Image) Voice Transciption
Transcription
- 클로바노트 https://clovanote.naver.com/
받아쓰기
Summary
-
Reference https://www.kaggle.com/code/blurredmachine/vggnet-16-architecture-a-complete-guide
-
Very Deep Convolutional Networks for large-scale image recognition
-
깊이가 깊어짐에 따라 overfitting, gradient vanishing, 연산량 문제 발생 - 극복 방법 제안
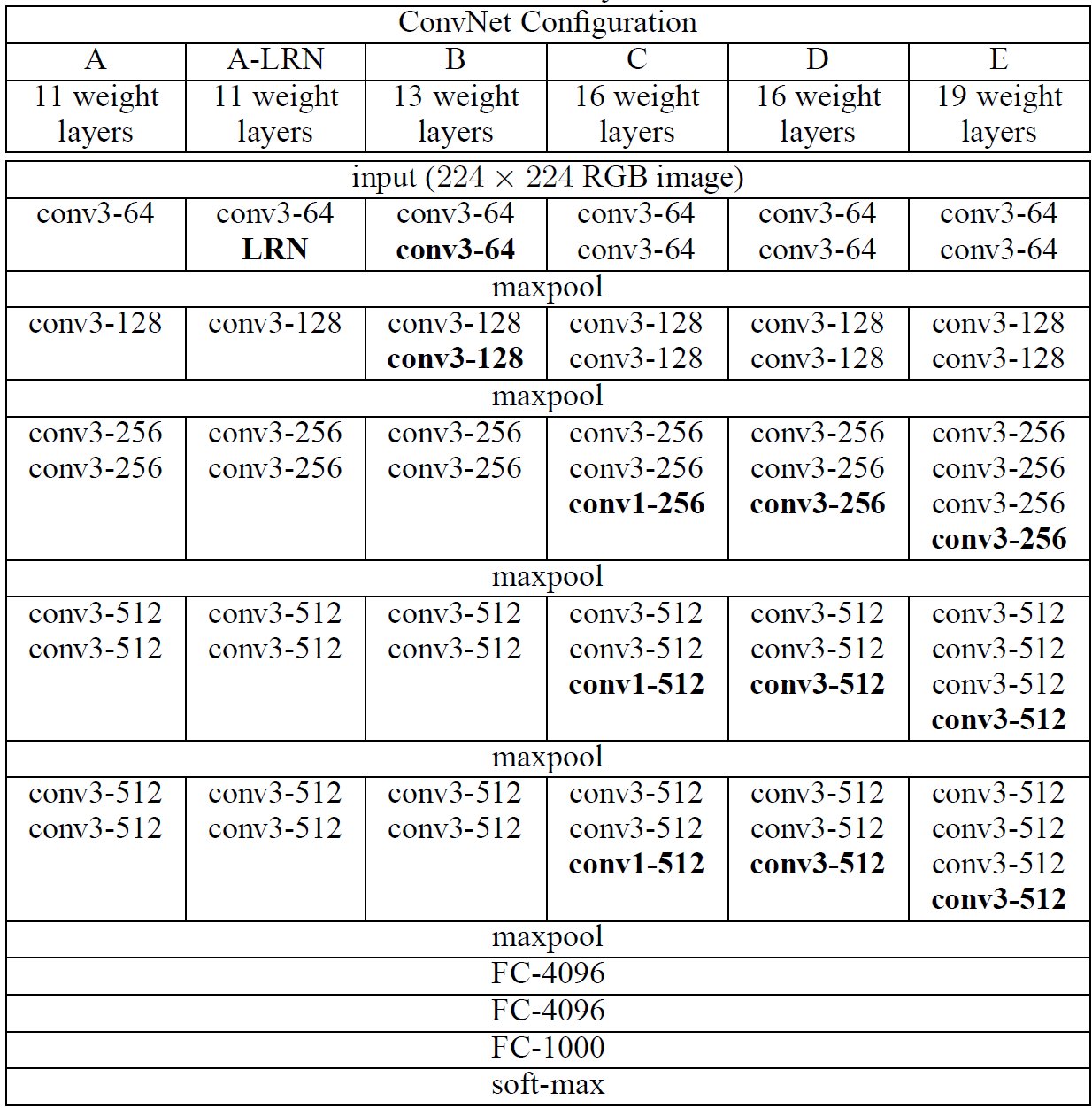
Configurations
A~E까지 layer의 개수에 따라 성능 차이를 살펴보았다.
-
input: RGB(3) x 224 x 224
- conv3-64: 3x3 kernel을 64개 사용하여, feature 64개를 추출했다는 뜻.
- padding, stride 정보는 표에는 나와있지 않으나, padding 1 stride 2 라고 한다
- layer의 갯수(VGG16) = convolution layer 2 + 2+ 3 + 3 + 3 + Fully connected layer 3 = 16개
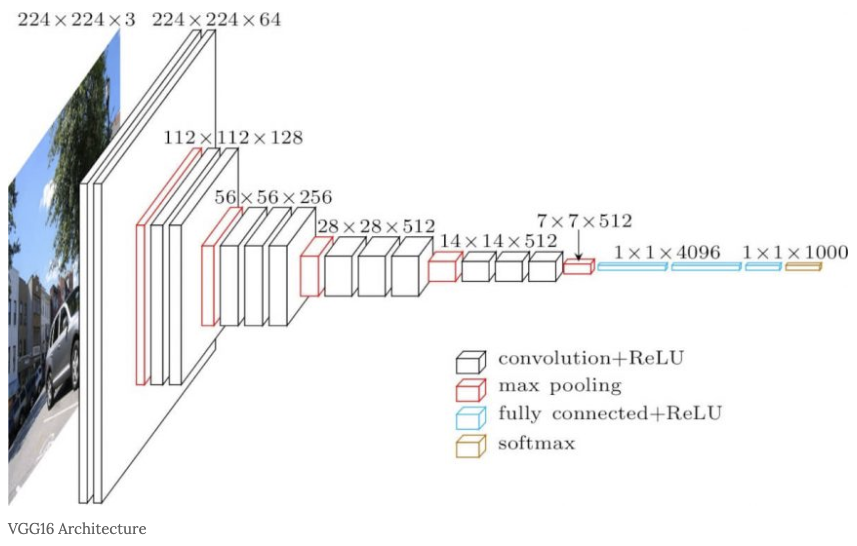
이 중에서 VGG16의 구조를 살펴보자.
원본 그림은 아래와 같다
자세히 각 단계를 풀이하면 아래와 같다(카글 참고)
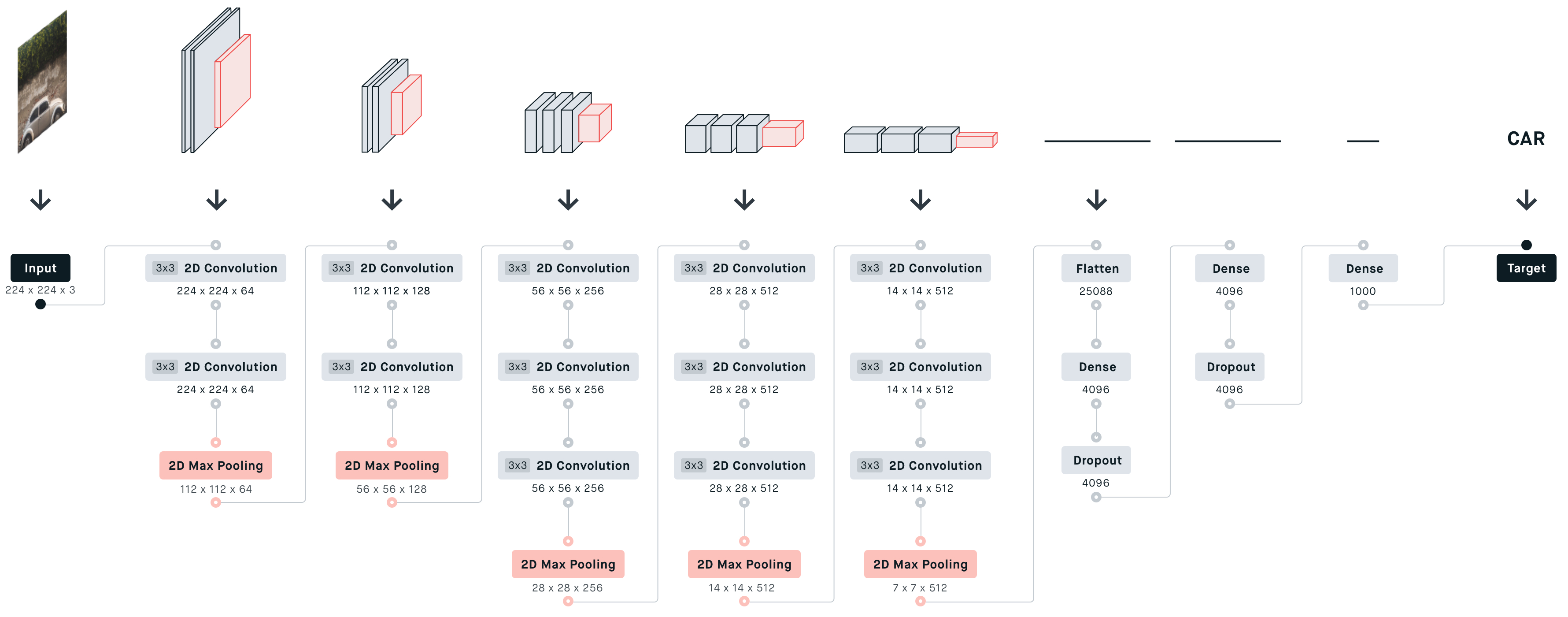
여기서도 layer 개수는 convolution layer와, fully connected layer만 세면 된다.
단계별 디테일 정보는 아래와 같다.
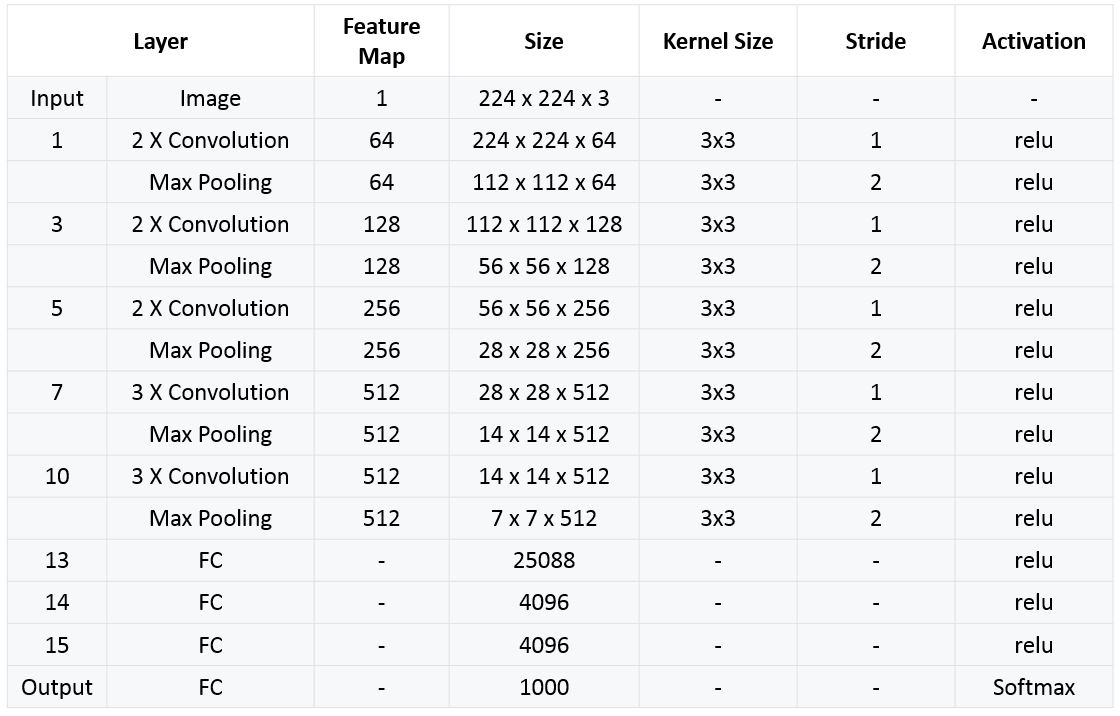
- 설명
- input: trainning set의 각 pixel에 평균 RGB 값을 빼준 전처리를 거친 224 * 224 RGB 이미지
- Convolution layers
- 입력된 이미지는 3 *3 필터를 적용한 ConvNet을 통과
- 비선형성을 위해 1 * 1 필터도 적용
- stride = 1
- 공간 해상도 유지를 위해 3 * 3 conv layer에 대해 1 pixel에 padding을 적용
- Max-pooling은 2 * 2 pixel 에서 stride = 2
- FC-layers
- 첫번째와 두번째는 각 4096개의 채널
- 마지막 세번째는 1000개의 채널
- Activation
- 모든 hidden layer에 Activation(활성화) 함수로 ReLU를 사용
- Softmax
- AlexNet에 적용된 LRN(Local Response Normalization)는 VGGNet 성능에 영향이 없기 때문에 적용하지 않습니다.
Training
-
The optimization method
- stochastic gradient descent SGD + momentum (0.9) with momentum
- batch size 256
-
Regularization
- L2 regularization
- L2 정규화는 오버피팅을 방지하기 위해 가중치(weights)에 페널티를 주는 방법입니다. 손실 함수에 λ×L2 Norm을 추가하여 계산합니다.
- weight decay 5e-4
- Dropout is after the first two fully connected layers, p = 0.5.
- Compare to AlexNet
- Depth and Size of Convolutions
- VGGNet이 AlexNet보다 깊고 (더 많은 레이어를 가짐), 작은 컨볼루션 필터를 사용한다는 점에서 내재적인 정규화(implicit regularization) 효과가 있다고 추측
- Pre-trained Layers
- VGGNet은 일부 레이어가 사전에 훈련되어 있을 가능성
- (추가 설명) “내재적인 정규화(implicit regularization)”란 모델 구조 자체가 오버피팅을 억제하는 특성을 가지고 있다는 것을 의미합니다. 예를 들어, VGGNet에서는 작은 컨볼루션 필터(예: 3x3)를 사용하여 더 깊은 네트워크를 구성합니다. 이렇게 하면, 각 레이어에서 수행되는 연산이 덜 복잡해져서 모델이 데이터에 오버피팅되는 것을 어느 정도 방지할 수 있습니다.
- Depth and Size of Convolutions
- L2 regularization
-
Parameter initialization :
- a shallow A network
- randomly initialized
- weight: sampled from N (0, 0.01)
- bias: initialized 0.
- deeper networks
- 처음 네 개의 합성곱 레이어(Convolutional Layers)와 세 개의 완전 연결 레이어(Fully Connected Layers)는 A 네트워크의 파라미터로 초기화됩니다.
- 그러나 나중에는 사전 훈련된 파라미터(pre-trained parameters)를 사용하지 않고도 직접 초기화할 수 있음이 발견되었습니다.
- a shallow A network
-
Input Image Size
- 각 재조정된(rescaled) 이미지에서 224 * 224 크기로 랜덤하게 자른(cropped) 이미지를 얻습니다.
-
Stochastic Gradient Descent
- 각 SGD 반복(iteration)에서 위의 랜덤 크롭 작업을 수행합니다.
-
Data Augmentation
- 자른 이미지는 랜덤하게 수평으로 뒤집히고(horizontally flipped) RGB 색을 변화시킵니다(color shifted).
특징
3x3 filter
- 그 전의 모델들은 11x11등 큰 것이 더 성능이 좋다고 알려져 왔었다.
- 장점
- 여러번 씀으로써, receptive field를 넓힌다.
- 3x3 두 번 통과 vs 5x5 한 번 통과
- receptive field: 둘 다 5x5
- parameter: 3x3x2=18개, 5x5=25개. 더 적은 파라미터 개수로 효율적으로 학습할 수 있다
- layer를 여러번 통과하니 비선형성이 증가한다
- 정보의 집중도: conv를 두 번하면 triangle, 한번하면 rectangle, fully connected는 상수값의 형태로 그래프가 그려진다. (노트 참고).이것은 장점이될 때도 있고 단점이 될 때도 있다. (각 장단점은 설명을 하지 않음)
1x1 filter
또한 Non-linearity를 증가시키기 위해 1x1 Conv. filter를 사용했는데 (GoogLeNet등의 경우에는 Parameter 수의 감소 목적으로 사용되었습니다.), 3x3 Conv. filter를 사용한 경우보다 오히려 성능이 더 안 좋아졌다 (뒤에 결과에 나옴). 결과에서 다시 언급하겠지만, 논문에서는 1x1 Conv. filter를 사용하면 Non-linearity는 높아지지만 Spatial한 Context 정보를 놓치기 때문 에 오히려 성능이 더 낮아졌다고 언급했다.
Hyper Parameter
- batch size = 256
- momentum = 0.9
- weight decay = 0.0005
- drop out = 0.5
- epoch = 74
- learning rate = 0.01(10배씩 감소)
Data Augmentation
-
224 * 224 size로 crop된 이미지 랜덤으로 수평 뒤집기
-
랜덤으로 RGB값 변경
-
Training image rescale 실험을 위해 3가지 방법으로 rescale을 하고 비교를 합니다.
-
input size = 256, 256로 고정
-
input size = 356 356로 고정
-입력 size를 [256, 512] 범위로 랜덤하게 resize 합니다. 이미지 안의 object가 다양한 규모로 나타나고, 다양한 크기의 object를 학습하므로 training에 효과가 있었다고 합니다. 빠른 학습을 위해서 동일한 배치를 갖은 size=384 입력 image로 pre-trained 된 것을 fine-tunning함으로써 multi-scale 모델을 학습시켰습니다.
구현
Tensorflow Code
Pretrained 된 VGG16 모델을 로드하여 VGG의 구조 확인 할 수 있는 코드입니다.
import numpy as np
import pandas as pd
import os
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
input_tensor = Input(shape=(224, 224, 3))
base_model = VGG16(input_tensor=input_tensor, include_top=True, weights='imagenet')
model = Model(inputs=input_tensor, outputs=base_model.output)
model.summary()
VGGNet 클래스 만들기
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense , Conv2D , Dropout , Flatten , Activation, MaxPooling2D , GlobalAveragePooling2D
from tensorflow.keras.optimizers import Adam , RMSprop
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.callbacks import ReduceLROnPlateau , EarlyStopping , ModelCheckpoint , LearningRateScheduler
def create_vggnet(in_shape=(224, 224, 3), n_classes=10):
input_tensor = Input(shape=in_shape)
# Block 1
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(input_tensor)
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
# Block 2
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
# Block 3
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
# Block 4
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
# Block 5
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
x = GlobalAveragePooling2D()(x)
x = Dropout(0.5)(x)
x = Dense(units = 120, activation = 'relu')(x)
x = Dropout(0.5)(x)
# 마지막 softmax 층 적용.
output = Dense(units = n_classes, activation = 'softmax')(x)
model = Model(inputs=input_tensor, outputs=output)
model.summary()
return model
모델 생성하기
model = create_vggnet(in_shape=(224, 224, 3), n_classes=10)
VGG16을 연속된 Conv를 하나의 block으로 간주하고 이를 생성할 수 있는 conv_block()함수 만듬.
- conv_block()함수는 인자로 입력 feature map과 Conv 연산에 사용될 커널의 필터 개수와 사이즈(무조건 3x3), 그리고 출력 feature map을 크기를 줄이기 위한 strides를 입력 받습니다.
- 또한 repeats인자를 통해 연속으로 conv 연산 수행 횟수를 정합니다.
from tensorflow.keras.layers import Conv2D, Dense, MaxPooling2D, GlobalAveragePooling2D, Input
from tensorflow.keras.models import Model
# 인자로 입력된 input_tensor에 kernel 크기 3x3(Default), 필터 개수 filters인 conv 연산을 n회 연속 적용하여 출력 feature map을 생성.
# repeats인자를 통해 연속으로 conv 연산 수행 횟수를 정함
# 마지막에 MaxPooling(2x2), strides=2 로 출력 feature map의 크기를 절반으로 줄임. 인자로 들어온 strides는 MaxPooling에 사용되는 strides임.
def conv_block(tensor_in, filters, kernel_size, repeats=2, pool_strides=(2, 2), block_id=1):
'''
파라미터 설명
tensor_in: 입력 이미지 tensor 또는 입력 feature map tensor
filters: conv 연산 filter개수
kernel_size: conv 연산 kernel 크기
repeats: conv 연산 적용 회수(Conv2D Layer 수)
pool_strides:는 MaxPooling의 strides임. Conv 의 strides는 (1, 1)임.
'''
x = tensor_in
# 인자로 들어온 repeats 만큼 동일한 Conv연산을 수행함.
for i in range(repeats):
# Conv 이름 부여
conv_name = 'block'+str(block_id)+'_conv'+str(i+1)
x = Conv2D(filters=filters, kernel_size=kernel_size, activation='relu', padding='same', name=conv_name)(x)
# max pooling 적용하여 출력 feature map의 크기를 절반으로 줄임. 함수인자로 들어온 strides를 MaxPooling2D()에 인자로 입력.
x = MaxPooling2D((2, 2), strides=pool_strides, name='block'+str(block_id)+'_pool')(x)
return x
VGGNet 모델 생성
def create_vggnet_by_block(in_shape=(224, 224,3), n_classes=10):
input_tensor = Input(shape=in_shape, name='Input Tensor')
# (입력 image Tensor 또는 Feature Map)->Conv->Relu을 순차적으로 2번 실행, 출력 Feature map의 filter 수는 64개. 크기는 MaxPooling으로 절반.
x = conv_block(input_tensor, filters=64, kernel_size=(3, 3), repeats=2, pool_strides=(2, 2), block_id=1)
# Conv연산 2번 반복, 입력 Feature map의 filter 수를 2배로(128개), 크기는 절반으로 출력 Feature Map 생성.
x = conv_block(x, filters=128, kernel_size=(3, 3), repeats=2, pool_strides=(2, 2), block_id=2)
# Conv연산 3번 반복, 입력 Feature map의 filter 수를 2배로(256개), 크기는 절반으로 출력 Feature Map 생성.
x = conv_block(x, filters=256, kernel_size=(3, 3), repeats=3, pool_strides=(2, 2), block_id=3)
# Conv연산 3번 반복, 입력 Feature map의 filter 수를 2배로(512개), 크기는 절반으로 출력 Feature Map 생성.
x = conv_block(x, filters=512, kernel_size=(3, 3), repeats=3, pool_strides=(2, 2), block_id=4)
# Conv 연산 3번 반복, 입력 Feature map의 filter 수 그대로(512), 크기는 절반으로 출력 Feature Map 생성.
x = conv_block(x, filters=512, kernel_size=(3, 3), repeats=3, pool_strides=(2, 2), block_id=5)
# GlobalAveragePooling으로 Flatten적용.
x = GlobalAveragePooling2D()(x)
x = Dropout(0.5)(x)
x = Dense(units = 120, activation = 'relu')(x)
x = Dropout(0.5)(x)
# 마지막 softmax 층 적용.
output = Dense(units = n_classes, activation = 'softmax')(x)
# 모델을 생성하고 반환.
model = Model(inputs=input_tensor, outputs=output, name='vgg_by_block')
model.summary()
return model
모델 생성하기
model = create_vggnet_by_block(in_shape=(224, 224, 3), n_classes=10)