AI Deep Dive, Chapter 9. 왜 RNN보다 트랜스포머가 더 좋다는 걸까?
AI Deep Dive Note
01 연속적인 데이터예시와 행렬과 벡터 식으로 RNN 이해하기
- 문장을 넣어서, 긍정 vs 부정 이진분류
- 주가를 넣어서, 내일 주가를 알려줘
- 동영상을 넣어서 (프레임의 연속) 어떤 동작이냐 분류 혹은 동작 점수를 알려줘
- 저는 강사 입니다
- 단어 -> 숫자로 바꾼다 (word embedding)
- 저는 [1, 0, 0] x_1
- 강사 [0, 1, 0] x_2
- 입니다 [0, 0, 1] x_3
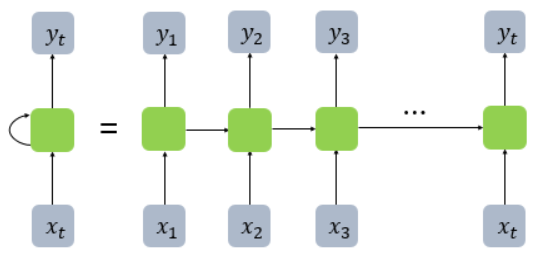
- Neural Network에 하나씩 순차적으로 넣어보자 (RNN의 접근법)
- 단어 -> 숫자로 바꾼다 (word embedding)
- RNN 동작 방식
- RNN: Recurrent Neural network

- 이렇게 함으로써 얻는 효과는?
- h2의 출력을 만들 때, h1도 고려한다.
- h3의 출력을 만들 때, h1, h2도 고려한다.
- 수식

- \[h_0 = 0\]
- \[h_1 = tanh(x_1W_x+b)\]
- \[h_2 = tanh(x_2W_x+h_1W_h + b)\]
- \[h_3 = tanh(x_3W_x+h_2W_h + b)\]
-
\(y_3 = h3W_y+b_y\) 얘는 activation따로 안하고, softmax를 통과시킬거라
-
tanh: -1~1까지, 최대 기울기 1정도는 됨. vanishing gradient에 취약
- h가 이전 정보를 담는 역할
추가 조사
순환 신경망(RNN)은 순차 데이터나 시계열 데이터를 이용하는 인공 신경망 유형입니다. 이 딥러닝 알고리즘은 언어 변환, 자연어 처리(nlp), 음성 인식, 이미지 캡션과 같은 순서 문제나 시간 문제에 흔히 사용됩니다.
입력과 출력을 시퀀스 단위로 처리 (시퀀스: 문장 같은 단어가 나열된 것)
- 메모리 셀: RNN의 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할을 하는 노드를 셀이라고 합니다. 이 셀은 이전의 값을 기억하려고 하는 일종의 메모리 역할을 수해하므로 메모리 셀이라고 부릅니다.
- 은닉층의 메모리 셀에서 나온 값이 다음 은닉층의 메모리 셀에 입력됩니다. 이 값을 은닉 상태라고 합니다.
02 RNN의 backpropagation과 구조적 한계를 직관적으로 이해하기
- HELL -> ELLO
- 다음에 어떤 알파벳(one hot encoded)이 나와야 할까?
- 다중분류
- \(\hat{y}\)를 softmax 통과시켜서, cross-entropy 계산
- ELLO 네개 글자에 대해 cross-entropy 더해주면 됨
- 근데, O(마지막글자)가 나오기 위해 H(맨 첫글자)가 주는 영향?
-

- 멀리 있는 입력의 영향이 낮다.
03 Plain RNN 실습
- plain RNN.ipynb 실행
04 seq2seq 개념 및 문제점과 실습까지
-
RNN 유형
- One to Many: 이미지에 대해 문장 출력 Man is playing piano
- Many to One: 정말 강추 합니다 -> 긍정지수 0.98
- Many to Many: 저는 강사 입니다 -> I am an instructor
- 번역은 이 구조 보단 seq2seq 구조를 사용함
-
seq2seq
-
도식
-
: start of sentens, 토큰 중 하나 -
: end of sentens. 토큰 중 하나. 단어와 똑같이 one hot encoding함. -
각 cell은 plain RNN에서 발전된 형태인 LSTM이나 GRU 주로 사용
-
추가 조사 내역
-
LSTM과GRU는 순환 신경망(RNN, Recurrent Neural Network)의 변형으로, 시퀀스 데이터를 처리하는 데 특화된 구조입니다:- LSTM (Long Short-Term Memory): LSTM은 “긴 단기 메모리”라는 의미로, 1997년에 Sepp Hochreiter와 Jürgen Schmidhuber에 의해 제안되었습니다. 기본 RNN의 단점인 장기 의존성 문제를 해결하기 위해 설계되었습니다. LSTM은 입력, 출력, 삭제 게이트(input, output, forget gates)라는 세 가지 특별한 구조를 가지고 있어, 정보를 저장하거나 삭제하는 메커니즘을 학습할 수 있습니다.
- GRU (Gated Recurrent Unit): GRU는 2014년에 Kyunghyun Cho 등에 의해 제안되었습니다. LSTM의 간소화된 버전으로 볼 수 있으며, LSTM보다 파라미터 수가 적습니다. GRU는 리셋 게이트(reset gate)와 업데이트 게이트(update gate) 두 가지 게이트만을 사용합니다. 이로 인해 계산 효율성이 좋아지지만, LSTM에 비해 모델의 용량이 작아질 수 있습니다.
두 구조 모두 시퀀스 데이터에서 장기 패턴을 학습하는 데 효과적이며, 특정 작업에 어떤 구조가 더 적합한지는 데이터와 문제의 특성에 따라 다를 수 있습니다.
- 두 구조 모두, 먼 곳의 입력 데이터가 흐려지는 문제를 완벽히 해결하지는 못했다.
- LSTM의 경우, 접근 방법은
- x_n을 담을 때, 얼마나 담을까(0-1 사잇값)도 학습시킨다
- 얼마나 담을지도, 멀면 잊혀져서, 학습이 잘 안된다
-
-
encoder, decoder 두 파트(서로 다른 RNN임)로 구성
- encoder의 마지막 h(context vector라고 함)를 decoder의 처음h로 사용

-
학습시엔 teacher forcing(지도 학습이라 가능), test 땐 출력 나온 것을 입력으로 사용
- I부터 He같은 것으로 잘못되면 도미노처럼 잘못된다는 단점이 있다.
-
seq2seq의 문제점
- 멀수록 잊혀진다. encoder, decoder모두 해당
- context vector에 마지막 단어(저는 강사 ‘입니다’)의 정보가 가장 많이 담긴다
- context vector: h
- 실습: seq2seq.ipynb
-
추가 조사
vanishing gradient를 막기 위해 ReLU를 사용하지 않는 이유
RNN(Recurrent Neural Network)에서 발생하는
vanishing gradient문제는 활성화 함수tanh또는sigmoid의 특성 때문에 발생하는 것이 맞습니다. 이러한 활성화 함수들은 그래디언트가 너무 크거나 작을 때 그래디언트의 값이 매우 작아지는 특성이 있습니다. 이로 인해 시간 스텝이 길어질수록 그래디언트가 점차 소실되는 문제가 발생합니다.그렇다면, 왜
ReLU를 사용하지 않는지에 대한 질문에 대한 답변은 다음과 같습니다:
- ReLU의 문제점: ReLU는
exploding gradient문제를 야기할 수 있습니다. ReLU는 음수 값에 대해서는 0을 반환하고, 양수 값에 대해서는 그대로 값을 반환하기 때문에, 그래디언트가 큰 값을 가질 경우 이 값이 계속 커질 수 있습니다. RNN에서는 시퀀스가 길어질수록 이러한 문제가 누적되어 모델의 학습을 방해할 수 있습니다.- Dying ReLU 문제: ReLU는 특정 상황에서 뉴런이 학습 도중에 활성화되지 않게 되는 문제, 즉 ‘dying ReLU’ 문제가 발생할 수 있습니다. 이는 특정 뉴런이 항상 0의 값을 출력하게 되어, 해당 뉴런이 더 이상 학습에 기여하지 않게 되는 현상입니다.
- RNN의 특성: RNN은 시퀀스 데이터의 특성 상, 긴 시퀀스를 처리할 때 그래디언트가 여러 시간 스텝에 걸쳐 누적되므로, ReLU의 선형 특성 때문에 그래디언트가 빠르게 폭발할 수 있습니다.
- LSTM과 GRU의 등장: RNN의
vanishing gradient문제를 해결하기 위해 LSTM(Long Short-Term Memory)과 GRU(Gated Recurrent Unit)와 같은 구조가 제안되었습니다. 이러한 구조들은 내부 게이트 메커니즘을 통해 그래디언트 소실 문제를 해결하였기 때문에, ReLU를 사용할 필요가 줄었습니다.결론적으로, RNN에서 ReLU를 사용하는 것은 그래디언트 폭발 문제와 dying ReLU 문제로 인해 학습이 어려울 수 있습니다. 따라서, RNN의 변형 구조인 LSTM이나 GRU를 사용하여 그래디언트 소실 문제를 해결하는 것이 일반적입니다.
추가 조사 2
Teacher forcing
Teacher forcing은 시퀀스 예측 작업에서 RNN(Recurrent Neural Network) 또는 그 변형 구조들(LSTM, GRU 등)을 학습시킬 때 사용하는 기법입니다.시퀀스 예측 작업에서 모델은 이전 시간 스텝의 출력을 현재 시간 스텝의 입력으로 사용합니다. 예를 들어, 번역 작업에서 “I am a student”를 “나는 학생이다”로 번역하는 경우, “나는”이라는 단어를 생성한 후, 이 단어를 다음 입력으로 사용하여 “학생이다”를 생성하게 됩니다.
그러나 학습 초기에는 모델의 예측이 부정확할 수 있기 때문에, 이러한 부정확한 예측을 다음 입력으로 사용하면 학습이 불안정해질 수 있습니다. 이를 해결하기 위해
Teacher forcing기법을 사용합니다.Teacher forcing의 원리:
- 학습 도중에는 실제 정답(ground truth)을 다음 시간 스텝의 입력으로 사용합니다.
- 예를 들어, 위의 번역 예제에서 “나는”을 생성한 후, 실제 정답인 “학생이다”를 다음 입력으로 사용하여 모델을 학습시킵니다.
- 이렇게 하면 모델이 부정확한 예측으로 인한 누적된 오류로부터 보호받게 되어 학습이 더 안정적으로 진행됩니다.
그러나
Teacher forcing만 사용하면, 실제 테스트 시에는 이전 시간 스텝의 모델 출력을 입력으로 사용해야 하므로, 학습과 테스트 시의 동작이 다르게 됩니다. 이로 인해 일부 경우에는 학습된 모델의 성능이 저하될 수 있습니다. 따라서, 학습 도중에Teacher forcing를 일정 확률로 적용하거나, 학습 초기에만 적용하는 등의 전략을 사용하기도 합니다.
05 RNN attention의 문제점과 트랜스포머의 self-attention
-
Beautiful insights for RNN
-
왜 plain RNN은 번역기로는 잘 안쓰일까?
-
무조건, 문장의 마지막 단어가 제일 중요하게 여겨짐.
-
LSTM, GRU가 있다지만, 근본적인 해결은 아님. why?
- 얼만큼 주울지도 학습하는데, 이것도 멀면 흐려짐
-
트랜스포머는 왜 성공했나 Attention is all you need pdf link
-
‘뭘’ 주목해야 하는 지를 학습함
- LSTM, GRU는 얼마나 주울 지를 학습함
-
내적 연산이 활용 됨
-
내적 - 얼마나 닮았는 지
-
import numpy as np def softmax(x): e_x = np.exp(x - np.max(x)) return e_x / e_x.sum(axis=0) def attention(query, key, value): # Query와 Key의 내적을 구합니다. scores = np.dot(query, key.T) # Softmax를 적용하여 Attention weights를 구합니다. attention_weights = softmax(scores) # Attention weights와 Value의 내적을 구하여 출력을 계산합니다. output = np.dot(attention_weights, value) return output, attention_weights
-
-
Attention은 트랜스포머 이전에 이미 있던 개념
-
RNN -> RNN + attention -> 트랜스포머로 발전
-
추가조사
- BERT (Bidirectional Encoder Representations from Transformers): Transformer의 인코더만을 사용하여 양방향으로 문맥을 파악하는 모델입니다. 주로 사전 학습(pre-training)과 세부 튜닝(fine-tuning)의 두 단계로 학습됩니다.
- GPT (Generative Pre-trained Transformer): Transformer의 디코더만을 사용하여 텍스트를 생성하는 모델입니다. BERT와 마찬가지로 사전 학습과 세부 튜닝의 두 단계로 학습됩니다.
- T5 (Text-to-Text Transfer Transformer): 모든 NLP 작업을 텍스트 대 텍스트 변환 문제로 간주하는 모델입니다.
- XLNet: Transformer와 순환 메커니즘을 결합하여 긴 시퀀스를 처리하는 데 효과적인 모델입니다.
- RoBERTa: BERT의 변형으로, 학습 데이터와 학습 방법을 최적화하여 BERT보다 더 좋은 성능을 달성합니다.
- ViT (Vision Transformer): Transformer 구조를 이미지 분류 작업에 적용한 모델입니다.
- DistilBERT, TinyBERT, MobileBERT: BERT의 경량화 버전으로, 계산 효율성을 높이면서도 비교적 높은 성능을 유지합니다.
-
RNN + attention의 문제: RNN 구조적 한계 두 가지 + 흐려지는 정보에 attention한다
- 쓰다라는 단어의 뜻을 이해하려면, 돈을, 모자를, 맛이, 글을 과 같이 멀리 있는 앞 단어를 봐야 알 수 있는데, h7에는 x1이 흐려진 채로 들어가 있으니 x7의 참의미를 못 담고 있다. 심지어 영어라면 뒤를 봐야 할텐데 뒤 단어들은 아예 담지도 않음 (bidirectional RNN 써야 함)
-
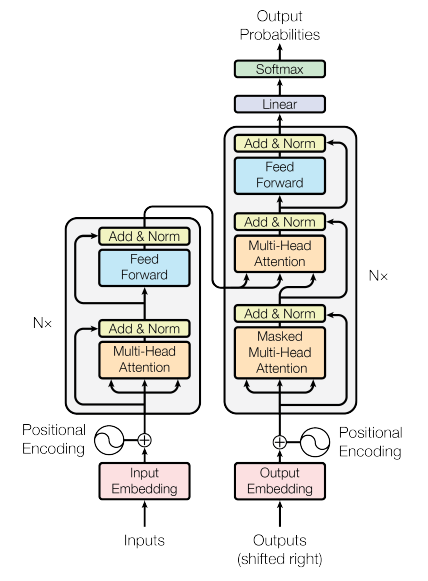
트랜스포머는 attention을 적극 활용, self-attention을 통해 RNN을 완전히 버렸다
-
Decoder가 마지막 단어만 열심히 보는 문제 (갈수록 흐려진다) <- attention으로 해결
-
RNN의 vanishing gradient (멀수록 잊혀진다) <- self-attention으로 해결
-
흐려지는 정보에 attention <- self-attention으로 해결
-

-
추가 조사
Self-Attention
Self-Attention은 Transformer 모델의 핵심 구성 요소 중 하나로, 시퀀스 내의 각 단어나 토큰이 다른 모든 단어나 토큰과의 관계를 계산하는 메커니즘입니다. 이를 통해 모델은 문장 내의 장거리 의존성(long-range dependencies)을 효과적으로 파악할 수 있게 됩니다.
Self-Attention의 기본 아이디어는 다음과 같습니다:
- Query, Key, Value: 각 단어나 토큰은 세 가지 다른 벡터로 변환됩니다. 이 벡터들은 Query(Q), Key(K), Value(V)로 불립니다. 이 변환은 각각 다른 학습 가능한 가중치 행렬을 사용하여 수행됩니다.
- Attention Score 계산: Query 벡터와 모든 Key 벡터의 내적(dot product)을 계산하여 Attention Score를 얻습니다. 이 점수는 해당 단어가 다른 단어와 얼마나 관련이 있는지를 나타냅니다.
- Softmax 적용: Attention Score에 Softmax 함수를 적용하여 확률 분포를 얻습니다. 이 확률 분포는 각 단어가 다른 단어에 주는 “주의”의 정도를 나타냅니다.
- Value 가중합: Softmax로 얻은 확률 분포를 사용하여 Value 벡터들의 가중합을 계산합니다. 이 결과는 각 단어에 대한 출력 벡터로 사용됩니다.
- 출력: 위의 과정을 통해 얻은 출력 벡터들은 최종적으로 다음 층으로 전달됩니다.
Self-Attention의 장점은 각 단어가 문장 내의 모든 단어와의 관계를 동시에 고려할 수 있다는 것입니다. 이로 인해 Transformer는 장거리 의존성을 효과적으로 학습할 수 있으며, 이는 RNN이나 LSTM과 같은 순차적인 모델보다 더 높은 성능을 달성하는 데 기여합니다.
-
-
-
-
-
06 강의 마무리 (딥러닝 연구는 뭘 잘해야 할까)
- 결국 직관을 바탕으로하는 아이디어 싸움
- 사전 정보를 잘 심어주자
- ex 1. 정보를 어떻게 엮는 게 좋을까?
- CNN: 위치가 가까운 픽셀들끼리 먼저 보고 (선택과 집중), 멀리 있는 건 나중에 정제해서 조합
- 트랜스포머: 단어들 간 관계 정보를 파악해서 번역하자
- ex 2. 이전 layer와 다음 layer는 값의 차이가 별로 없을 것이다.
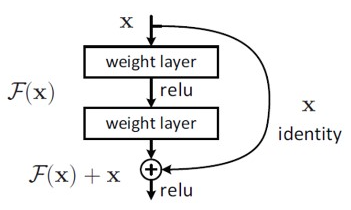
- ResNet의 skip connection
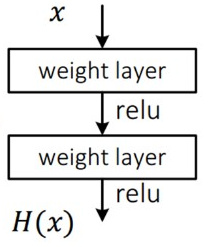
- Residual (잔차)를 학습한다
- 기존에는 x->F(x)를 만드는 것을 학습했다면, 여기선 그 차이값 H(x)-x를 학습한다.
- 신경망이 깊을 수록, 그 전 레이어와 다음 레이어의 차이가 크지 않다는 사전정보를 준 것이다.
- 도식
- 기존
- ResNet
- 블로그 링크 매우 설명이 잘 되어 있다
- ResNet의 skip connection
- ex 3. loss는?
- 회귀 문제니까 MSE로
- 출력이 확률 분포니까 cross-entropy로
- overfitting 방지를 위해 weight의 크기도 같이 고려해 봐야겠다 -> regularization
- ex 1. 정보를 어떻게 엮는 게 좋을까?
-
수식은 양념(설득력을 뒷받침)
- 인간은 어떻게 알까? 생각 또 생각