AI Deep Dive, Chapter 8. 왜 CNN이 이미지 데이터에 많이 쓰일까?
AI Deep Dive Note
01. CNN은 어떻게 인간의 사고방식을 흉내냈을까?
- 이미지 데이터에 대해서 잘 동작 함
- ex. object detection
- 신경다발을 잘 끊어냄 (FC-MLP 대비 잘 끊어냄) - 이미지를 인식할 때 뇌의 일부분만 활성화 되더라
- 첫 layer에서 모든 값을 다 보는 게 좋을까? 아니다
- 위치별 특징을 추출함
- 위치 정보를 유지한 채로 특정 패턴(특징)을 찾는다
- 패턴? 컨볼루션은 위치별 패턴을 찾는 연산이므로, 신경망에 적용함으로써 위치별 패턴이 있다는 사전 정보를 잘 준 것이다.
- FC layer는 픽셀 위치를 서로 막 바꿔 학습하는 것과 다를 바가 없음
- convolution으로 얻는 효과는?
- 가까이 있는 것들만 연결 = 위치 정보를 잃지 않음 -> 담당 노드라는 의미가 생김
- 퍼즐 처럼 섞으면 결과가 달라진다. FC랑 다르게
- 가까이 있는 것들만 연결 = 위치 정보를 잃지 않음 -> 담당 노드라는 의미가 생김
- 2x2 커널에 bias도 포함해서 총 5개 값을 학습한다
02. CNN은 어떻게 특징을 추출할까?
- 세로 패턴이 있는 이미지
- 내적을 생각하면 알 듯이, 필터와 비슷한 패턴이 나왔을 때 값이 크다.
- 가로 패턴이 있는 이미지
- 실제 이미지에 적용해보니, 엣지다
-
이미지에 변형을 가하기도 한다. Blur -> 커널에 따라서, box car 5x5
- 여러 필터링 결과물을 결합할 때에는, 옆으로 쌓는 게 아니라, depth 방향으로 쌓는다. 그래야 위치 정보가 남아있다. 이걸 feature map이라고 부른다
convolution layer가 FC layer와 다른 점
- 주변만 연결 (신경망을 잘 끊어서, 위치 정보를 잃지 않는다)
- weight 재사용 (쭉 긁으면서 스캔하니까 눈이 바닥에 있어도 인식)
- 여러 종류의 필터로 여러 종류의 특징을 추출
- 각 필터가 어떤 특징을 추출하는 지를 머신이 학습한다.
- 가로필터, 세로필터, 대각선필터… 이걸 지정하는 게 아니라 학습하는 것
- Q) conv layer로 FC layer 표현할 수 있을까?
- 100x100 입력 이미지에, kernel size 100x100, filter 종류 10개 사용하는 conv layer는 10000->10인 FC layer와 동일
03. 3D 입력에 대한 convolution
- 컬러사진이면 RGB 3개 채널
- 무조건 앞에 거 채널 수에 맞춘다 = 필터도 3개 채널임. 3x5x5 -> 75개의 값들이 더해져서 하나의 값으로 나온다 / 혹은 depth wise convolution, RGB 따로 처리하는 방법도 많이 쓴다.
- 필터 여러 개에 의해서 여러 개의 피쳐맵이 나온다
04 Padding, Stride and Pooling
- Padding
- edge를 0으로 채움.
- 처리된 이미지의 사이즈를 유지하기 위함
- zero padding / zero insertion
- zero padding: 주변 값을 0으로 채움. 원치 않는 에지가 생김
- zero insertion: 데이터 샘플링 비율을 높이기 위해 (업샘플) 중간 사이사이에 0을 채워 넣음. 후에 low pass filtering을 통해서 적절히 0 값을 보간해 줌.
- Stride
- pooling에서 건너 뛰는 값
- Pooling
- 사이즈를 줄여 넓은 범위를 대표할 수 있게 함. 파라미터 필요 없음
- average pooling - 대표값으로 평균값
- max pooling - 대표값으로 최대값
- size=(4, 4)=이미지사이즈면, global average pooling(GAP)라고 부름
- depth 방향(채널수)는 유지이고, row, column만 리사이즈 함
05 CNN의 Feature map 분석 - 직접 구현한 실험 결과 공유
- convolution, pooling을 반복하다보면, 점점 더 넓은 범위, 점점 더 많은 특징을 대표하게 됨
- low level feature: 좌-우 에지, 상-하 에지, 대각선 에지, 재질 등등
- middle level feature: 다운 샘플링된 내에서의 그런 것들. 상대적으로 큰 구조물에 대한 정보임
- high level feature: 더 다운 샘플링된 내에서의 그런 것들. 상대적으로 거의 머리, 다리 수준의 표지임.
- 신기한 점: 성공한 그림은 max pooling을 많이한 레이어에서, weight들을 싹 다 더해보니, 실제 물체가 있는 위치에 주목했다. 실패한 그림은 그 외의 배경에 주목했다.
- 주의: 이렇게 훈련된다는 것이 아니라, 이런식으로도 해석할 수 있다 정도
- 미분해서 반대 방향으로 갔더니, 그렇게 나왔을 뿐이지, 뭘 뽑아냈는지 인간도 머신도 모름
06 VGGnet 모델읽기
- Very Deep Convolutional Networks for Large-Scale Image Recognition pdf link
- VGG는 이미지 그룹 이름 University of Oxford, Visual Geometry Group
- VGGNet은 옥스포드 대학의 연구팀에 의해 개발된 모델로써, 2014년 ILSVRC에서 준우승한 모델입니다. 이 모델은 이전에 혁신적으로 평가받던 AlexNet이 나온지 2년만에 다시 한 번 오차율 면에서 큰 발전을 보여줬습니다.
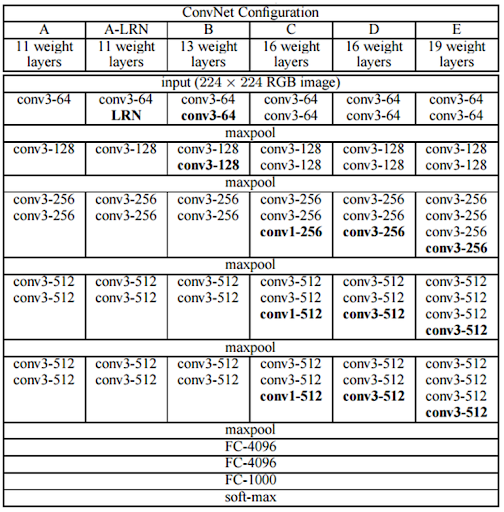
- Configurations
- 네트워크 깊이에 따른 네트워크 성능을 연구하기 위해, 여러 가지 구성(configuration) 실험 수행
- 깊이와 성능 사이의 관계를 연구하기 위해 실험적으로 도입. VGG16과 VGG19가 인기.
- VGG11(A), VGG13(B), VGG16(D), VGG19(E) - 계층 갯수가 뒤에 숫자로 붙는다.
- 합성곱 계층, 활성화 함수, 풀링 계층, 마지막 3개의 Fully connected layer
- 모든 구성은 동일한 fully connected layer를 사용, 차이점 - 합성곱 계층의 수와 구성
- 네트워크 깊이에 따른 네트워크 성능을 연구하기 위해, 여러 가지 구성(configuration) 실험 수행
- 핵심 아이디어
- 3x3 크기의 작은 필터를 사용하여 합성곱을 수행.
- 작은 필터를 여러 번 연속으로 적용하면 큰 필터를 한 번 적용하는 것과 동일한 수용 영역 (receptive field)를 얻을 수 있다.
- 깊이의 중요성:
- 깊이가 성능에 큰 영향, 깊은 네트워크가 더 복잡한 특징을 학습할 수 있음을 확인
- 3x3 크기의 작은 필터를 사용하여 합성곱을 수행.
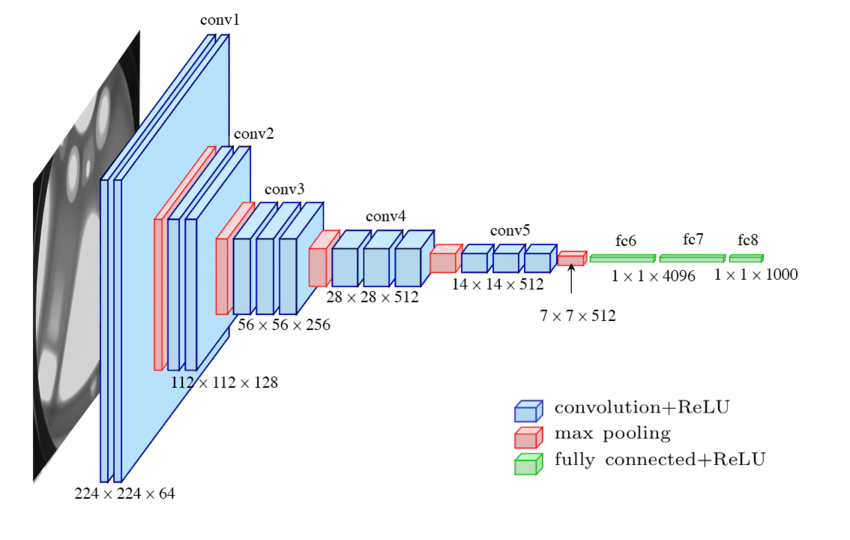
- D configuration의 도식
- 3x224x224
- 개 채 행 열
- 첫번째 레이어 사이즈
- 1개 이미지 x 3(RGB) x 224 x 224
- conv3-64: convolution with 3x3 kernel가 64개: 64x3x3x3
- padding 1을 한다고 논문에 써있음
- 즉, conv3-64라는 표기는 커널. 64x3x3x3
- 64x224x224
- 두번째 레이어 사이즈
- 필터 커널 conv3-64: 64x64x3x3
- 64x224x224
- 세번째 레이어 사이즈
- maxpool (2)
- 64 x 112 x 112
- conv3-128: 128x64x3x3
- padding 1
- 128 x 112 x 112
- …
- 512x7x7
- FC 4096
- 강의 워딩
얘를 한줄로 쭉쭉 피는 거에요 512 by 7 7 짜리가 쭉 있잖아요 MLP를 통과시킨다고 했습니다 그러면 MLP 통과? 이거는 이진분류, 다중분류 때 항상 했던 거죠 노드를 하나 만드는 데 있어서 싹 다 연결하는 거다라고 했었어요 그 노드 하나 만드는 데 512 곱하기 7 곱하기 7 만큼의 weight가 필요한 거 맞습니다 그래서 weight가 엄청 많이 필요해요 여기서 노드 하나 만드는데. 이러한 노드를 4096개를 만드는 게 FC 4096의 정체입니다 그러면 결국 4096이 되겠죠. 노드의 개수를 얘기하면 되는 거니까 쫙해서(512x7x7의 에지를 가리키며) 노드 하나, 또 쫙해서 노드 둘, 또 쫙 해서 노드 셋, 이렇게, 쭉 해서 총 4096개까지 노드를 만든다라는 겁니다. - 정리: 간단히 말하면, FC 4096 계층은 512x7x7 크기의 피쳐맵을 4096개의 노드로 변환하는 역할을 합니다. 각 노드는 피쳐맵의 모든 값을 입력으로 받아 하나의 출력 값을 생성합니다.
- weight의 개수는 95%는 fully connected layer에 있다. (비효율적)
- 강의 워딩
- FC 4096
- 그 담에 또 FC 4096 써 있네요. 이건 뭐겠어요. Fully connected
- FC 4096
- FC1000: 1000?
- 1000
- 왜 1000개? 클래스가 1000개인 문제를 풀고 싶어서.
- 이후에 softmax 통과시킴
- cross entropy해서
- 3x224x224
-
VGGNet의 종류
07 VGGNet 실습
- 모델을 다운받아서 실습.
- vgg19 사용
- fully connected layer가 용량을 다 사용하고 있다.
- 500MB정도
from torchsummary inport summary
print(load_model)
summary(load_model, input_size=(3, 224, 224))
08 Beautiful Insights for CNN
- summary of CNN
- convolution을 왜 쓰는가? 적은 수의 weight로 위치별 특징 추출
- 사진입력에는 반드시 특정 패턴 or 특징이 있고 픽셀 값들 위치 마구 섞으면 인식 불가
- convolution은 위치별 패턴 or 특징을 찾는 연산이다. 신경망 잘 끊어서 선택과 집중
- CNN 통과하면서 그 패턴들이 곱하고 (뭐가 더 중요한 특징?) 합해진다 (조합된다)
- low -> high level features
- 여러번 conv layer를 통과하는 이유?
- receptive field가 넓어진다
- 넓은 컨텍스트, 계층적 특징 학습
- 단점: 계산부하, 과적합, 정확도 저하
- 픽셀값을 만들기 위해, 두 레이어 건너서 생각해보면 3x3 커널 두개를 통과하는 거니 5x5로 receptive field가 넓어진다.
- 5x5 filter를 한번에 통과하면 되는 것 아니냐?
- 문제는, 무조건 넓을수록 좋은 것은 아니다. 이미지 사이즈까지 키우면, 그냥 fully connected layer이다.
- 3x3 두 번 vs 5x5 한 번
- 파라미터 수
- 5x5: 파라미터 25개
- 3x3 2번: 파라미터 9+9 = 18개
- 더 적은 수의 파라미터로 같은 receptive field를 얻었다. (VGGNet 논문에 써있음)
- 비선형성
- activation을 두 번 지나면서 비선형성을 좀 더 확보(VGGNet 논문에 써있음)
- 집중도
- 영역 vs 집중도 관점에서, 5x5는 커널 영역 내를 균일(box car)하게 봄. 3x3은 중앙은 좀 더 보고, 가장자리는 살짝 봄. (triangle)
- 강사 생각
- 중앙을 집중해서 보는 것이, 사람의 인식과 닮아있다.
- zero padding - max pooling 연산에서 edge를 걷어낸다.
- 파라미터 수
- receptive field가 넓어진다
- 마지막에 MLP를 통과하는 이유?
- 처음엔 먼 것과 연결을 끊었지만, 나중엔 각 영역별 특징을 싹 다 보고 결정해야
- object 뿐만 아니라, 배경 등의 맥락도 볼 필요가 있다
- 가장자리에 중요한 정보가 있을 수 있다. 데이터 augmentation할 때 일부분을 자른다
- 처음엔 먼 것과 연결을 끊었지만, 나중엔 각 영역별 특징을 싹 다 보고 결정해야
다른 설명
- 분류(Classification) 작업: VGGNet의 주요 목적은 이미지 분류입니다. Fully Connected Layer(완전 연결 계층)는 합성곱 계층(Convolutional Layer)에서 추출된 특징들을 바탕으로 최종적으로 이미지가 어떤 클래스에 속하는지 결정하는 역할을 합니다. 이 계층은 모든 특징을 고려하여 최종 예측을 수행합니다.
- 고차원 특징 학습: 합성곱 계층은 지역적인 특징을 추출하는 데 탁월하지만, Fully Connected Layer는 이러한 지역적 특징들을 조합하여 더 복잡하고 고차원적인 특징을 학습할 수 있습니다.
- 모델의 일반화: Fully Connected Layer는 학습 데이터의 다양한 패턴을 포착하고 일반화하는 데 도움을 줍니다. 이를 통해 모델은 새로운 데이터나 약간 변형된 데이터에 대해서도 잘 동작할 수 있게 됩니다.
- 연산의 단순화: Fully Connected Layer는 모든 입력 노드와 출력 노드 간의 연결을 가지므로, 연산이 단순화됩니다. 이는 학습과 예측 과정에서의 계산 효율성을 높이는 데 도움을 줍니다.
그러나 최근의 딥러닝 연구에서는 Fully Connected Layer의 파라미터 수가 많아 과적합(overfitting)의 위험이 있고, 연산 부하가 크다는 단점이 지적되기도 합니다. 이에 따라, 많은 최신 아키텍처들은 Global Average Pooling과 같은 다른 방법을 사용하여 Fully Connected Layer를 대체하거나 줄이는 경향이 있습니다.
-
max pooling을 너무 많이 한다면? 공간적인 정보를 너무 잃는다
-
CNN은 connection을 어떻게할 지 고민을 다시 해본 것이다(위치정보)